
We were honored to welcome Guanhong Li from the National University of Singapore to Nature AI Lab for an inspiring guest lecture. His research on diffusion models and LLMs in urban design, cultural modeling, and planning evaluation reminded us of the human and practical possibilities behind generative AI.
We are glad to share his research link:
https://research.nus.edu.sg/civic-resilience/
https://www.guanhongli.com/
Nature AI Lab
2025-10-19
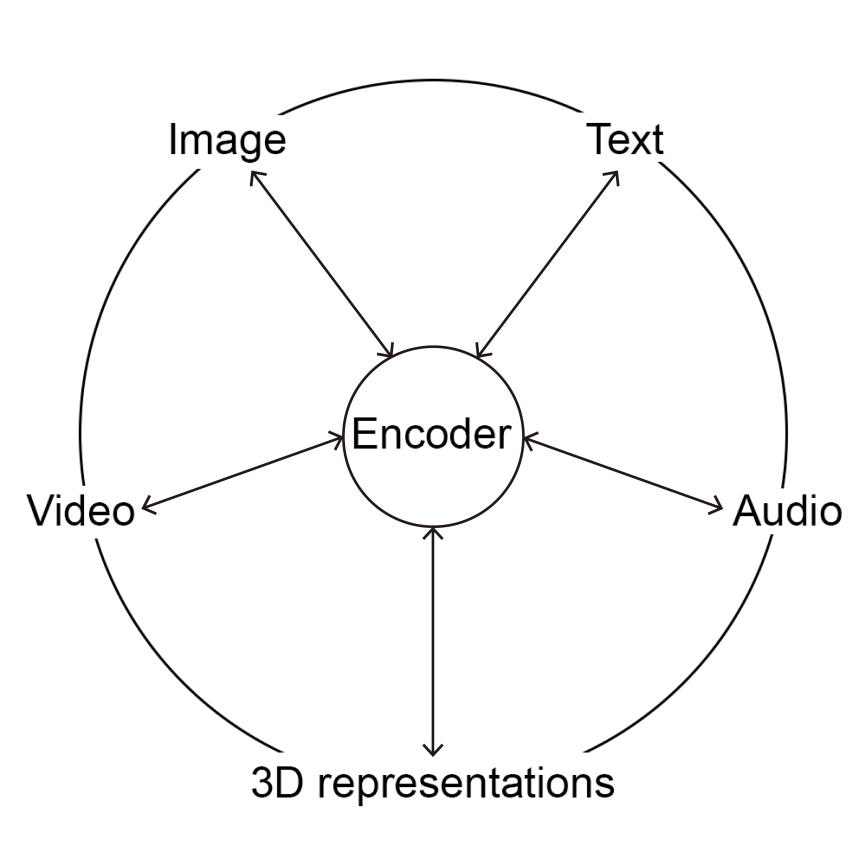
Cities Before They Are Built :
Generative Models are good at Domain Translation. At a recent guest lecture hosted by NatureAI Lab, PhD. student Guanhong Li from National University of Singapore in Critical Urban Theory and Data Study for Asian Context explained how diffusion models and Large Language Models (LLMs) are evolving from image synthesis tools with systems that understand density, form, and urban structure.
Figure 1. Domain translation structure across modalities. Image created by Guanhong Li.
Generative Adversarial Networks (GANs) as an Example
Li mentioned that Generative Adversarial Networks (GANs) illustrate how generative models support domain translation and practical tasks in the built environment. A GAN learns the data distribution through adversarial training and generates realistic samples that bridge modalities or styles. “Applications of generative models can be grouped into three functions: data synthesis, design automation, and data augmentation” Li said that. Prior reviews in architecture and urban analytics document these uses across data types and scales. They also position GANs as a flexible baseline despite the rise of diffusion models.
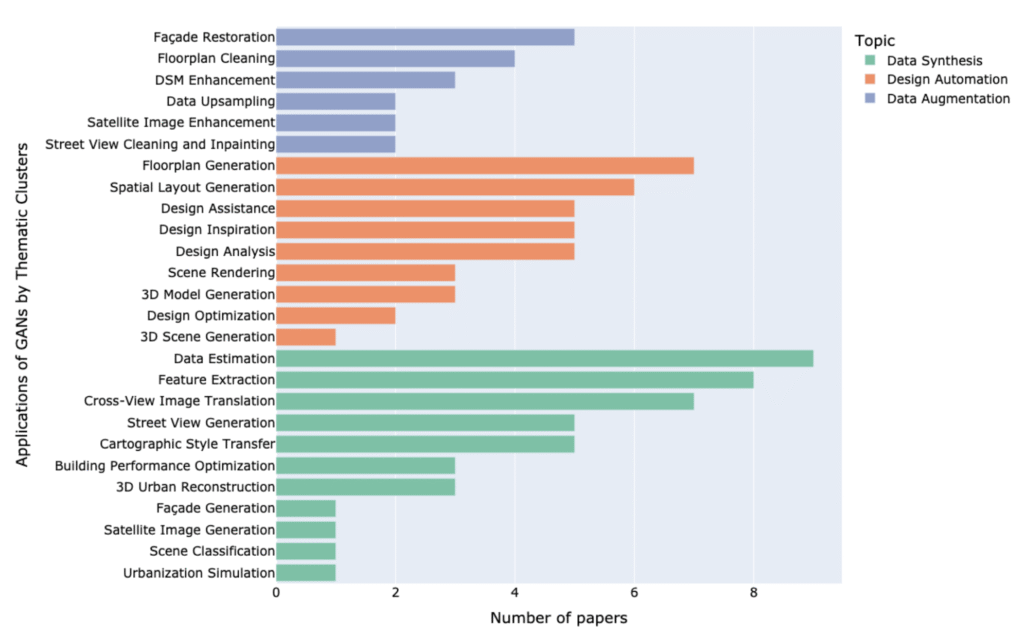
Figure 2. Thematic classification of GAN applications in the built environment, grouped by task type: Data Synthesis, Design Automation, and Data Augmentation.
Source: Wu, A. N., Stouffs, R., & Biljecki, F. (2022). Generative Adversarial Networks in the built environment: A comprehensive review of the application of GANs across data types and scales. Building and Environment, 223, 109477. https://doi.org/10.1016/j.buildenv.2022.109477
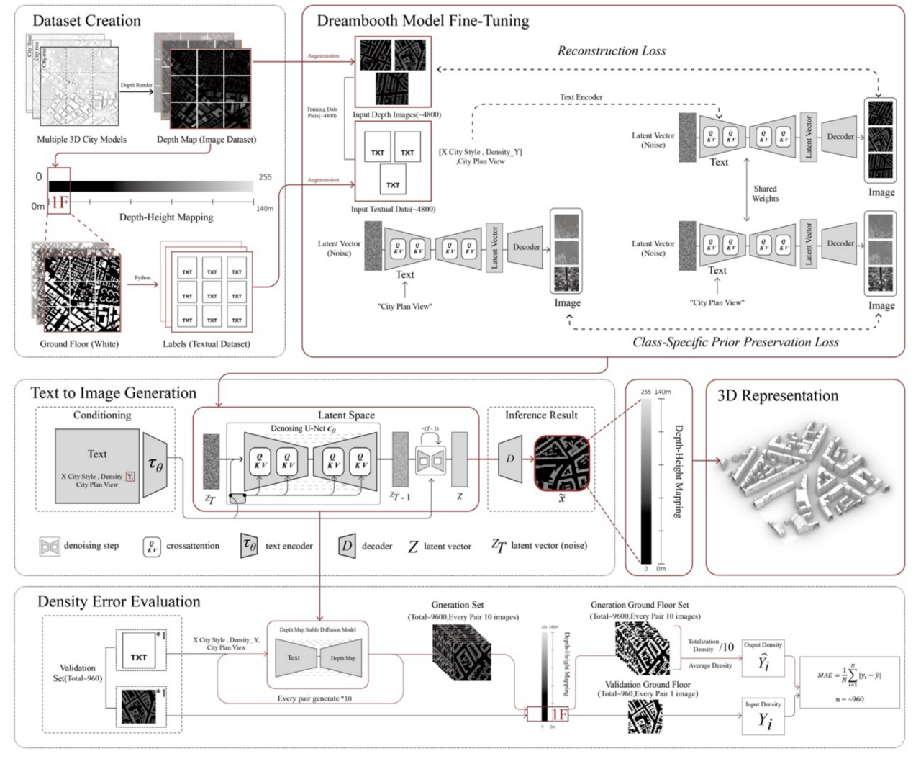
From Text To 3D City Blocks
Li presented “Text-to-City,” A framework that pipeline generates a grayscale map from text. It first performs conditioning on parcel boundaries, road network, land use semantics, and target density. It then runs controlled diffusion sampling under mask or conditional inputs. Finally, the 2D output is imported into Rhino for 3D reconstruction and processing. Meanwhile, Li’ s team designed 3 density expression formats to standardize prompts: natural-language description, level scale (Level n), and numerical actual value (Density_k). The model can generalize accurately within the specified density range. A second finding is that the model reconstructs rooftop types correctly. Besides, the model can generate consistent greyscale images while keeping density indicator accurate when using inpainting plugin. The lecture showed Text-to-City’s “style fusion” application: it uses controlled diffusion for morphological interpolation, block massing and rooftops to transition smoothly from one urban texture to another..
Figure 3. Full pipeline of the Text-to-City framework with data, model, generation, and evaluation stages.
Source: J.L. Zhuang, G.H. Li, H. Xu, J.T. XU, R.J. Tian (2024). Text-to-City: Controllable 3D Urban Block Generation with Latent Diffusion Model. In ACCELEERATED DESIGN, Proceeding of the 29th International Conference of the Association for ComputerAided Architectural Design Research in Asia (CAADRIA) 2024, vol.2, pp. 169-178
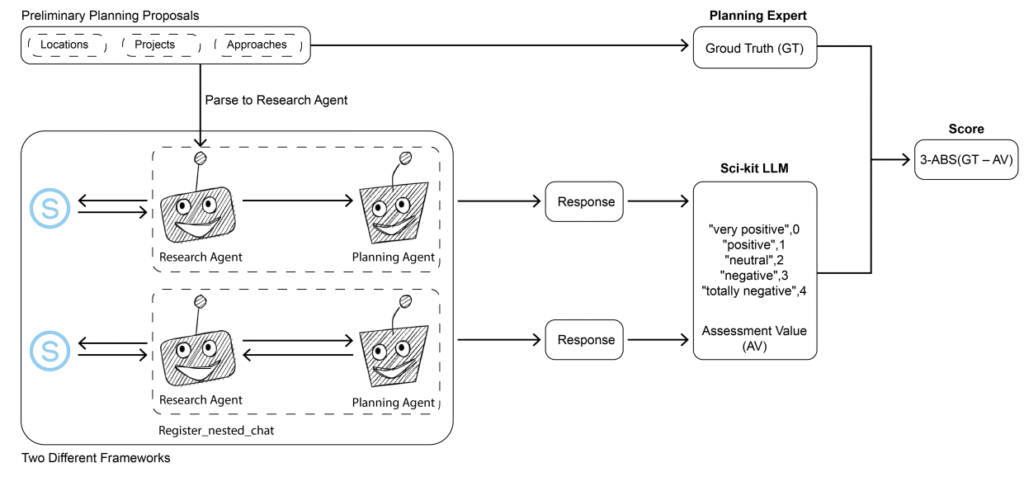
LLMs As Planning Evaluators
Li’ team asked three questions: Can LLMs help draft and evaluate planning proposals? How well do they perform? Which model should we use? They assembled 63 real proposals with expert scores. The scores were split into three parts: site, project, and approach, with weights and sensitivity tags. Two evaluation setups were tested: a sequential setup and a nested setup. Several models were run in both, including GPT-4o, Llama-3.2-3B, Ministral-8B, and Phi-3-mini. In overall results, Llama-3.2-3B under the nested setup matched or slightly exceeded GPT-4o. The nested setup also aligned better with human scores. By category, Llama-3.2 was broadly comparable to GPT-4o. One limitation is that the model gives conservative scores on site sensitivity, project coherence, and policy impact. “ LLMs are still need to be proved for planning review ”, Li said.
Figure 4. Framework for evaluating preliminary urban planning proposals
Source: Rico Carranza, E., G.H. Li, Huang, S.-Y (2025). LLM Planning Agents: Exploring the Potential and Challenges of Large Language Model Agents in Urban Design and Planning. The 30th International Conference of the Association for ComputerAided Architectural Design Research in Asia (CAADRIA).
Text-to-Park: Understanding Design Logic, Not Just Images
The Text-to-Park project asked whether non experts can describe a park in plain language and receive a usable layout. Using Stable Diffusion with ControlNet, the model aligned colors with functions and produced road and planting hierarchies without direct labels. Then the workflow details how the dataset was built. The team first selected highrated parks and scraped OSM features. Then applied center cropping and a fixed color scheme, and prepared satellite and Google Earth basemaps to create layout examples. An automatic labeler produced text prompts that record geometric shapes, elements, absolute and relative positions, spatial relations, and background. Augmentation used rotation, flipping, and squaring. The model was then trained and 2 checkpoints were compared. The report lists sample sizes, epochs, learning rate, batch size, and loss, and shows generated examples. The main finding is clear: Checkpoint 1 follows prompts well but struggles with boundary control; Checkpoint 2 processed boundaries better but follows prompts less strongly.
The team then examined boundary control using four methods: Inpainting, LoRA, ControlNet segmentation, and a refinement pass with Checkpoint-2. For each, Li report the setup, inputs, outputs, and a short takeaway. Inpainting redraws the whole masked region and only works when the color logic stays consistent. LoRA has trouble with abstract prompts that describe design rather than a picture. When background cues are removed during training, Checkpoint-2 produces weak park layouts.
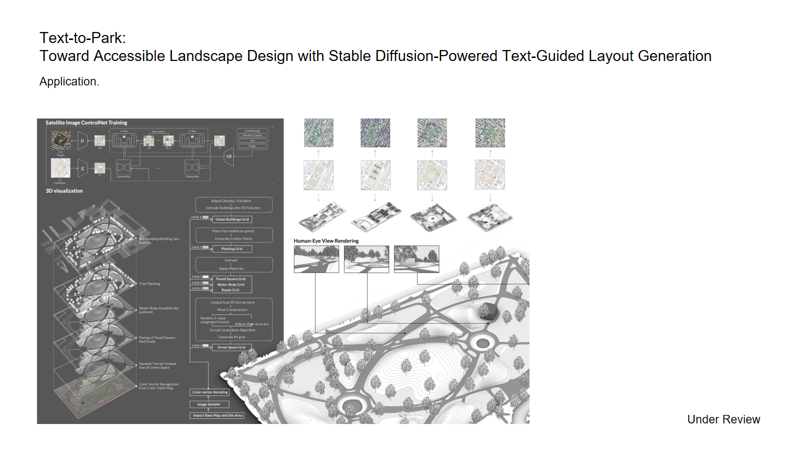
Figure 5. Workflow for generative park design using ControlNet, combining satellite imagery conditioning, color decoding, multi-layer terrain generation, and human-eye rendering.
Source: Text-to-Park: Toward Accessible Landscape Design with Stable Diffusion-Powered Text-Guided Layout Generation (Under Review).
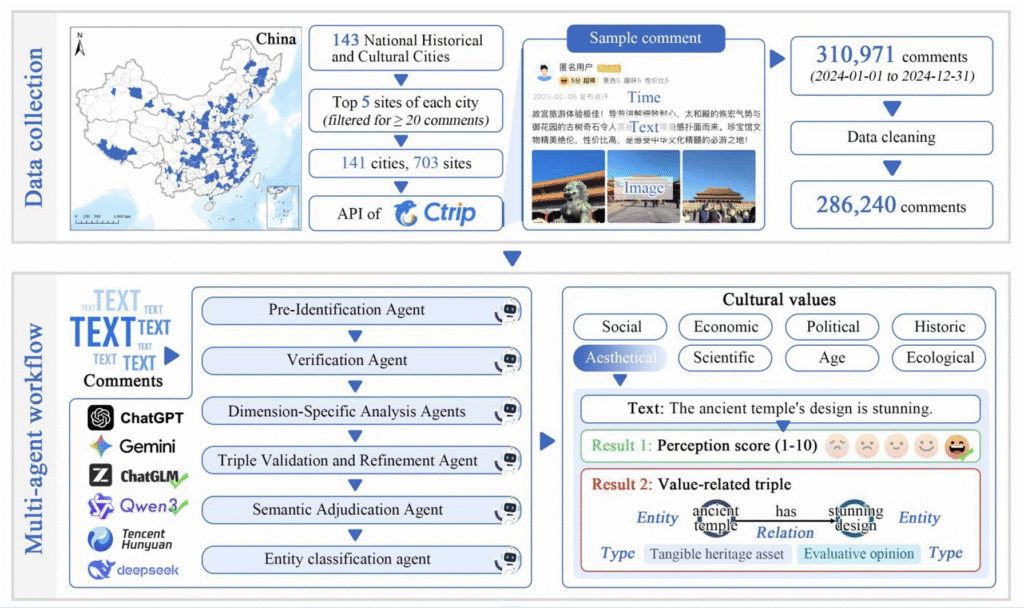
Cultural values in urban data
This section has 2 questions. How can a multi-agent LLM extract cultural values from social media, and how can unstructured text be turned into structured data. The study collects data from the Ctrip API, covering 141 Chinese cities and 703 cultural heritage sites. The pipeline uses several agents: a pre-identification agent, a verification agent, dimension-specific analysis agents, a triple validation and refinement agent, a semantic adjudication agent, and an entity classification agent. Cultural value is measured on 8 dimensions: social, economic, political, historical, aesthetic, scientific, age, and ecological. The analysis maps perception scores for 703 sites across 141 cities and examines links with urban characteristics. A triple normalization dictionary and an entity typing dictionary support construction of the Cultural Heritage Perception Graph (CHPG). To support structured representation, “the page also provides a triple-normalization dictionary and an entity-typing dictionary” Li said.
Figure 6. Data collection and multi-agent workflow for extracting cultural values from online comments across 703 heritage sites.
Source: A multi-agent large language model workflow for analyzing perceived cultural values from social media: A study of 141 Chinese cities (Under Review).
With an application, the workflow integrates with a RAG system for question answering. Using the Badaling Great Wall as an example, a query-parsing agent identifies the site, the target dimension, and sentiment for a single-dimension query. A hybrid retriever then uses entities, relations, query embeddings, and frequency signals to pull high-frequency positive and negative triples and supporting text from the CHPG. For cross dimension queries, the system collects evidence with all 8 dimensions and compiles a single summary.
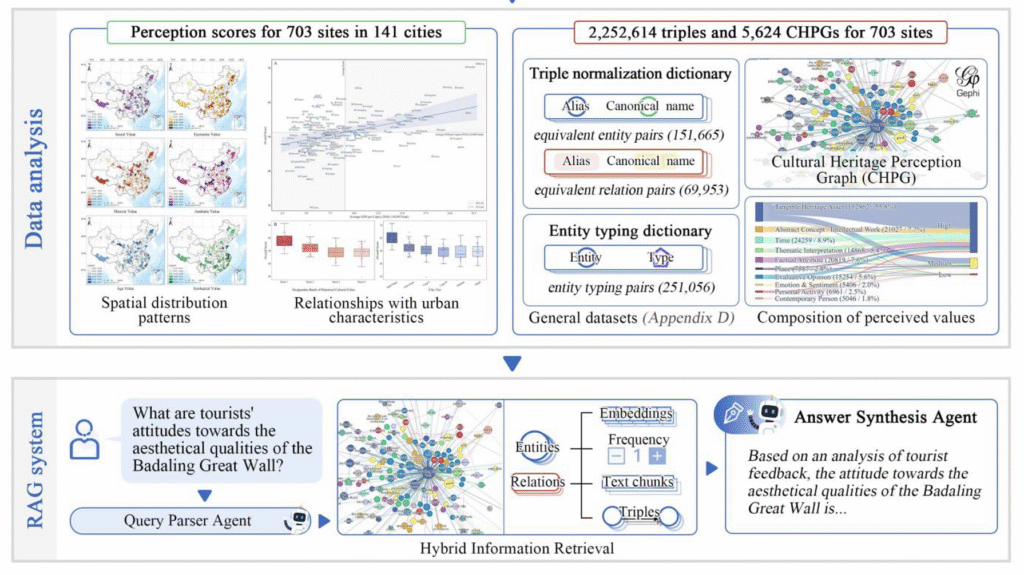
Figure 7. Workflow of the Cultural Heritage Perception Graph (CHPG) system
Source: A multi-agent large language model workflow for analyzing perceived cultural values from social media: A study of 141 Chinese cities (Under Review).